
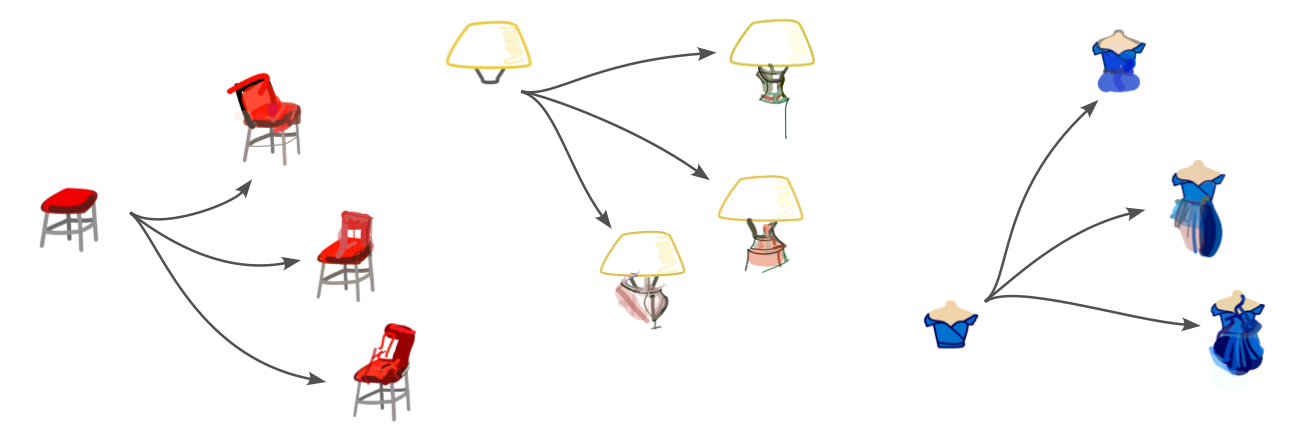
Co-Creative Drawing AI
CICADA is a collaborative, interactive and context-aware drawing agent for co-creative design. This models seeks to steer away from the paradigm of one-shot generation and bring the humans back in the loop by allowing real-time interaction.
The model combines CLIPDraw with penalization methods to build a custom cost function which takes the user's input into account in a flexible way. This lets the AI to bend the user's input without writing over nor disregarding it. Pruning and reinitialization methods are introduced to prevent thre process from getting stuck.
The interface allows for real-time control over some of the model's parameters by using sliders, and choosing which parts of the drawing are finished and not to be messed with. The prompt can also be changed at any instance if the user has a better idea. Check out the video!
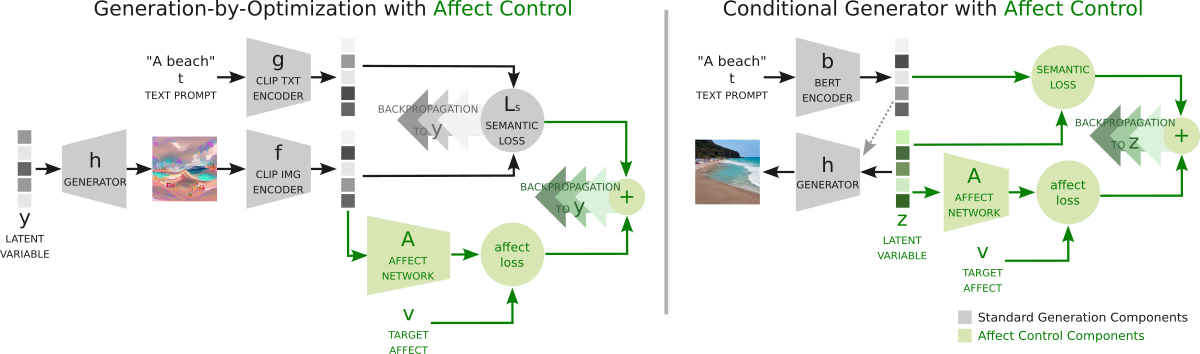
Affect-Conditioned Image Generation
Creating an image evoking certain affect in the viewer can be challenging through prompt-writing alone. Instead, we propose controlling affective content through a three-dimensional space used by psychologist to assert how an image or sentence makes you feel in terms of Valence (happy vs unhappy), Arousal (excited vs calm) and Dominance (in control vs submissive).
After training a neural network to predict affect based on language embeddings, we developed two affect-conditioning models to work with generation-by-optimization methods such as VQGAN+CLIP or prompt-conditioned generators such as Stable Diffusion.
You can play around with the following images of "a river", generated with Stable Diffusion to see how it works.
Valence





Arousal





Dominance





Naturally, the method works for any prompt, and also allows for controlling more than one affect dimension at once, but running Stable Diffusion takes some computing power. However, if you have a GPU and want to see it in action, you may clone the Github repo, install and run it locally.
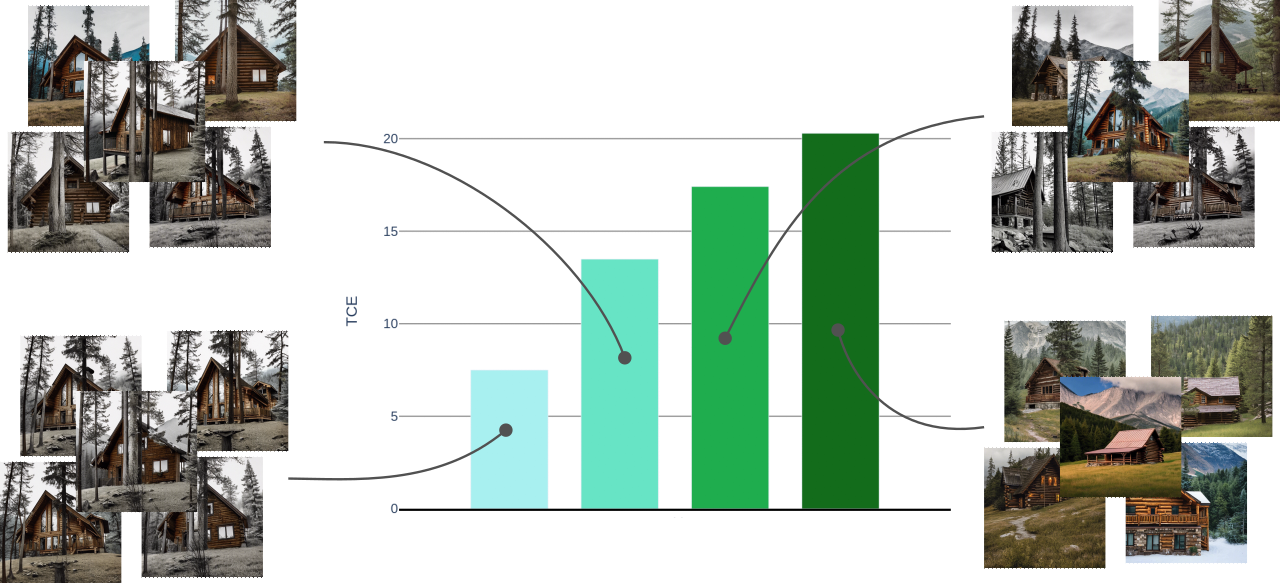
Image and Text Diversity
Diversity is a key component for assessing quality of AI-generated outputs. The user often does not seek solely for an answer of an image, but rather a set of different options from which to choose, and masuring the diversity of those options is a crucial step for ensuring the quality of the model.
Most traditional methods of achieving this are based on comparing the probability distribution of the data to that of the results, but that often needs a lot of samples and a dataset that in the era of pretrained models we just do not have.
So here's an easy way of assessing image (or text) diversity
$ pip install image-diversity
$ python3 image diversity <path/to/dir>